LUCIENDMENSAH
Trans* Twitter Project Intro
An Update on the Cool Work I'm Doing!
Updated Project Goals
The goal of this project is to explore how Twitter users use language and neologisms to express gender freedom. Some of the questions that I would like to hopefully answer are:
Is there an alignment between the pronouns that people use to describe themselves and the words that they use?
Do those that use pronoun sets outside of "he/him" and "she/her" tend to create more words to fit their identities?
What is the general sentiment of these neologisms with specific reference to those who may be outside the gender binary?
How often do people use neologisms to talk about themselves vs others?
Some smaller questions that I also would like to look at:
How many Twitter users do actually put their pronouns in their bios/location?
Is it more common to put pronouns in their bio or their location?
Data Pulling Code
I pull this data using Tweepy, a Python library designed specifically for interacting with Twitter. It also requires that I have Twitter Dev Access, which is something that I acquired a while ago. I start off by importing the necessary libraries - in addition to Tweepy, I need re for my regex, pandas to read the CSVs and matplotlib for visualizations.

After that, it is necessary to be authenticated through Twitter, and I have hidden my keys.

I set up the list of features that I will be looking for to create my dataframe, I have a list of the queries I will be searching for, and I have a dictionary that will make the process easier for looping through.

I am focusing on neologisms in English, so I set my language to English. The max number of tweets I can pull per query is 100 terms, so I set that, and then I begin a loop to search for tweets that are in my query, match the language, and match the number of tweets. I should note that with the labels "transwoman" and "transman", it is specifically spaced out in my code, but it still captures instances of "transwoman" and "transman", which is specifically marked as okay as a self-identifier but there has been discourse about which version is politically correct. My viewpoint is that one should separate the two, as "trans" is an adjective modifying "man" in the same way that "cis" is oftentime (silently) modifying man or woman. Putting the adjective and noun together may often be seen as a form of othering to differenciate a trans person from a cis person purposefully to deny their womanhood or manhood.

My code to search through tweets uses regex to search through a user's bio and location to see what set of pronouns they use. Right now, I am only looking for he/him, they/them, she/her, it/its, xe/xir/xem, ze/zir/zem in regards to pronouns since those are the sets that I have come across the most. As I encounter new sets of pronouns, I do my best to add them to this list. This code could also possibly use some refinement as it may make more sense to make each of the pronouns into a list and then do regex from there. All the pronouns are appended to their respective lists, and then I also have a specific list for users that do not have pronouns in their bio. From there, I am able to reference the previously created list to compile the dataframe since users that have at least one instance of a pronoun will be captured, and if a specific user uses multiple sets of pronouns, the dataframe will mark each of these. This allows for a variety of pronouns and possibly identities to be captured.

Data Examination
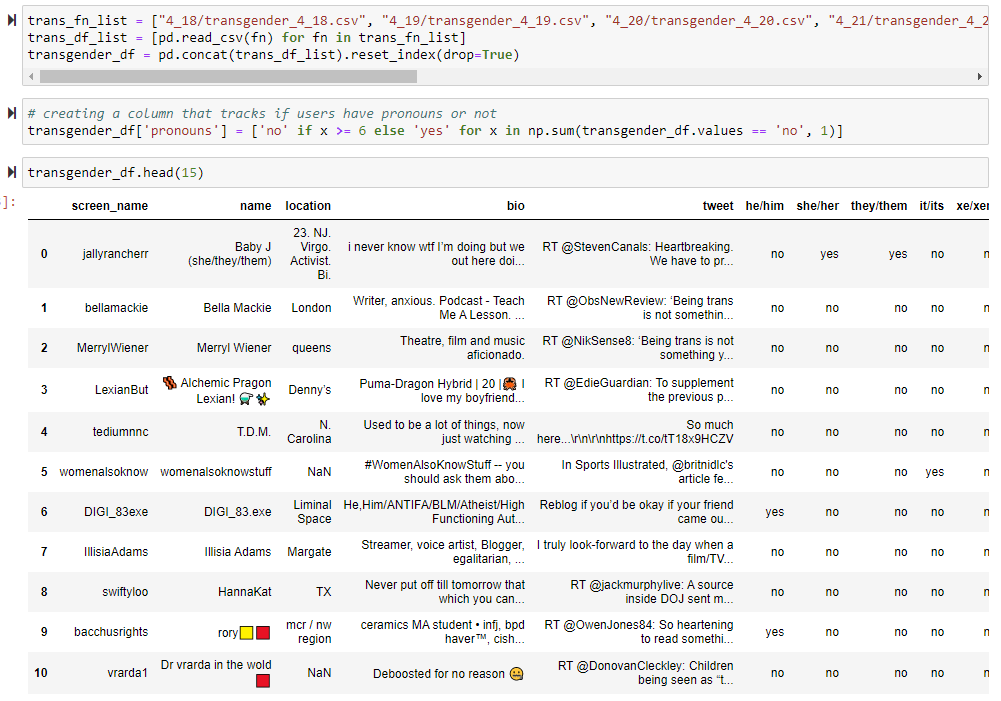
I will be pulling data from Twitter every other day, from a query of the words: "thembo", "bimbo", "himbo", "theydies", "ladies", "gentlethem", "gentlemen", "theybie", "transgender", "transwoman", and "transman". Each of these terms will be pulled in, and will be in their own csv file. An example of one of the datasets is available below:

As we can see from the preview of the data, we get a user's screen_name (user name), their name (display name), location (the reason why it is included is because some users put their pronouns in their location), bio (the most popular place to put pronouns), the tweet that had the word that was queried, which in this case was "thembo", and columns that specifically denote what set of pronouns were indicated either in their bio or location. I used regular expressions specifically searching for different pronoun sets in order to create the columns that indicated what pronouns they used. I figured this would be the most benefiticial while doing the data analysis. One issue with the data is that the Twitter indiscriminately will include users that may not specifically Tweeted a certain word, but also has it in their bio or their screen name, as we see for the first person. I, however, have not removed them from my analysis because those users show example of using one of the gendered neologisms as a self-identification, which is the main point of my research. Additionally, the main reason I am using pronouns is because they are another hallmark of self identification, though, while dealing with the different words in the queries, we will be interacting with the societal implications that each word has. For example, "bimbo" being aligned with women, "himbo" with men, and "thembo" being created to align with non-binary people. There is a fine line with this research as someone may be non-binary but not use they/them pronouns or vise-versa. That is why I will be trying to stray away from making such specific alignments, but we do live in an overarching cis-centric society.
Data Analysis
The next step is to compile the created dataframes together throughout the dates that have been collected. In order to make my findings statistically significant, I have about 1,000 tweets per query, which is all Tweeters - those who don't have pronouns in their bios and those that do. Reminder that I have 11 queries, which puts us at 11,000 data points. Wow! Since I want to look specifically at users with pronouns in their bios, that will likely remove about half of the data, but before we do that, we can answer one of my questions by looking at the number of people who have pronouns in their bios compared to those who don't.
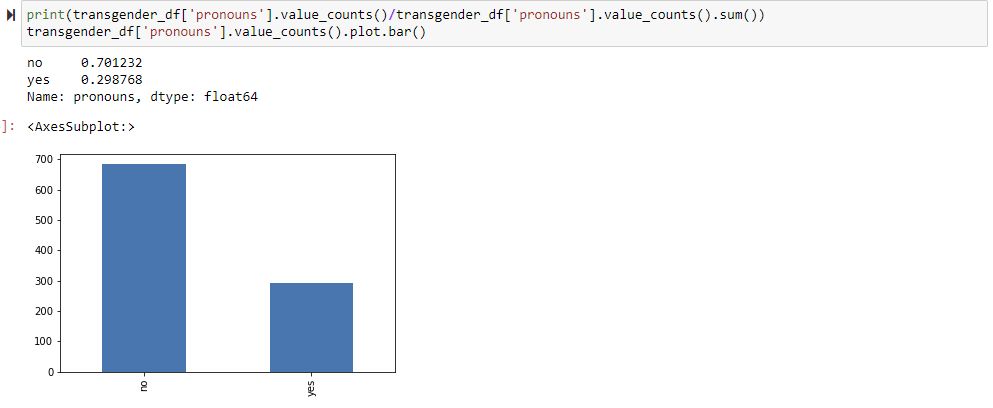
Seeing that most people don't use pronouns in their bio for tweeting a word as general as "transgender" is not surprising. What would be interesting to look at is if there is the same thing with different groups. "Transgender" would be the control and "trans man" and "trans woman" would be my differing variable. Let's compile these dataframes, add a pronouns column, and then visualize this distribution.

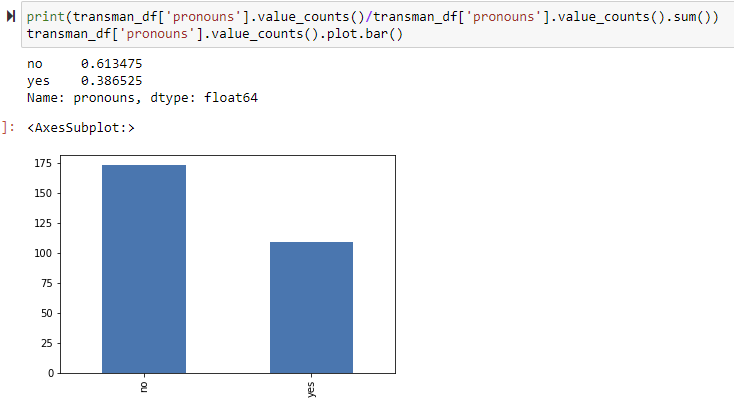


So, we see significantly less tweets in "trans man" than "trans woman" and "transgender", BUT the amount of people using pronouns is not that different than those terms. It would likely be helpful to look at the porpotional differences between them. However, removing people who don't have pronouns would lessen our dataset by more than half, but I still believe my findings would be statistically significant. Let's take a look at the other terms.

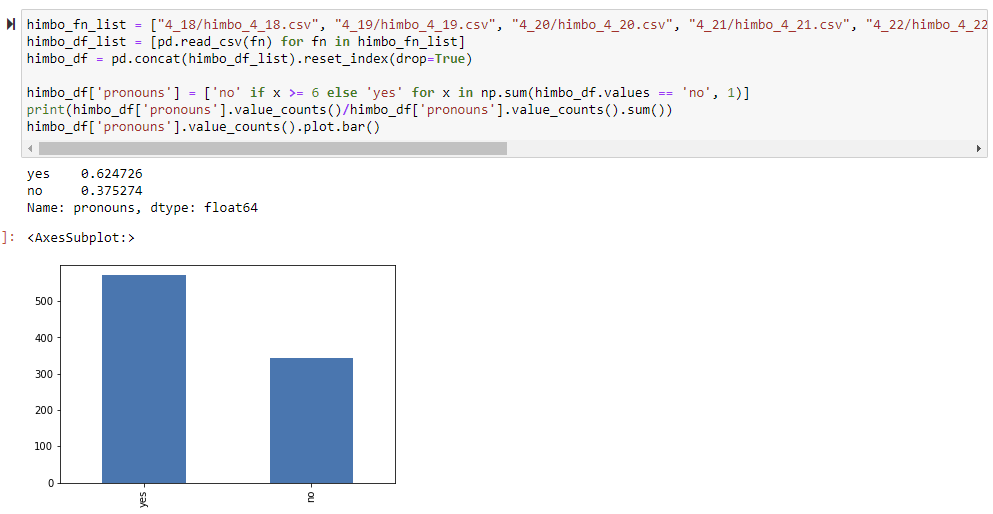
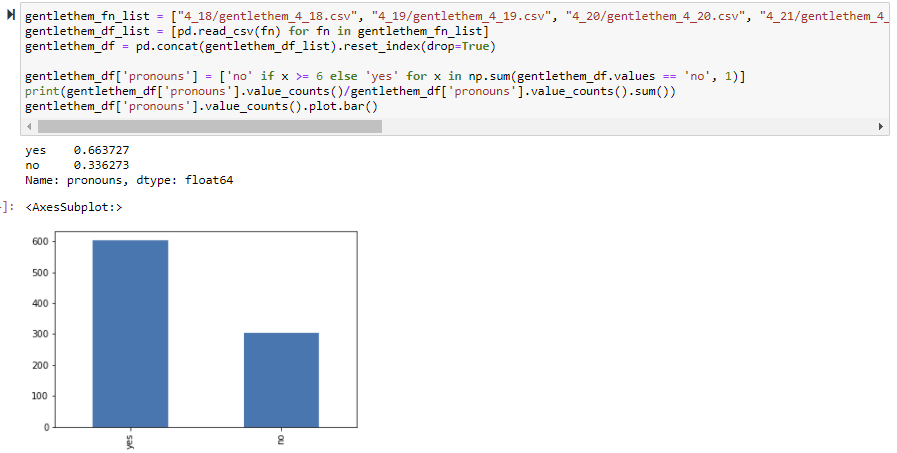
Whoa! More people have pronouns in their bio when they use the word himbo! Let's pause here and look at the distribution on their pronouns!
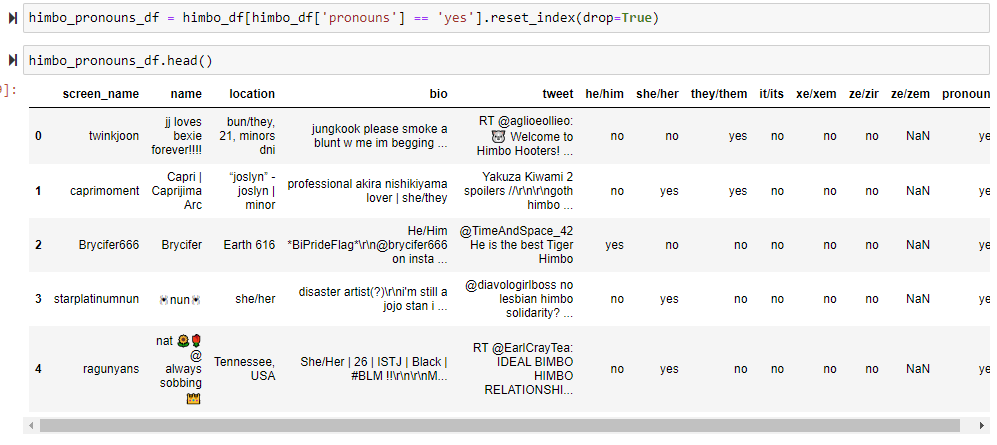
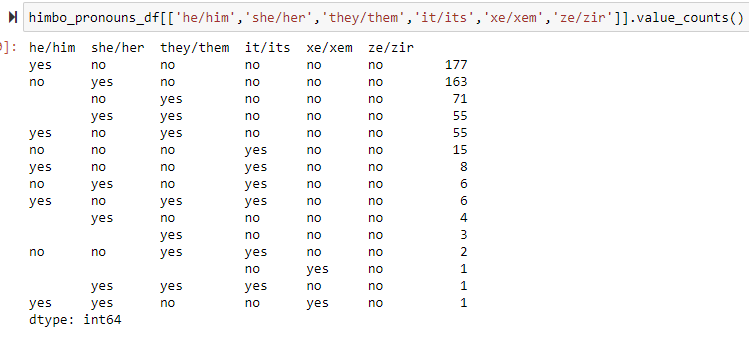
Heyyyy! This is kind of proving my hypothesis, that people's pronouns do kind of align with the word that they use, since himbo has the 'him' suffix, the assumption is that we would expect more he/him users, and that's true! At least, so far. Additionally, I like this distribution of the value counts because it also visualizes people with more than one set of pronouns. I am open to more visualizations that may also show the distribution of pronouns (maybe a pie graph?) Let's do this same thing for thembo and bimbo.

Omg... and we see the same thing for they/them and thembo. Most of the people tweeting that word do also use they/them or a combination of another pronoun set with they.
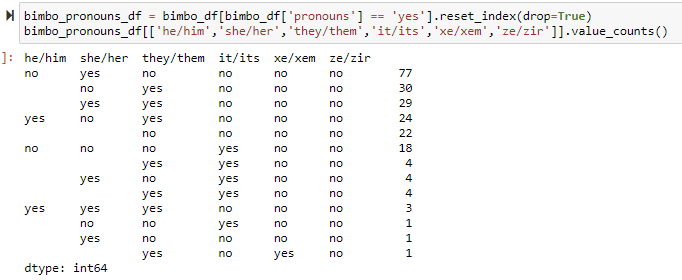
Whoa... So far, there is an alignment between the pronouns and the suffix/societal implications that a word has. Now, the deeper question is whether this is being used to talk about themselves or a group that they are a part of, or whether this is being used to talk about other people. But for now, this is pretty significant. Now, let's go ahead and see if we find the same kind of thing for the other queried words.



Overall, what we can tell from this is that words with specific gender morphemes tend to appeal more to people who reside within communities where it is the norm to indicate your pronouns to be more inclusive. This is cool! Since my next question is wondering who people are referring to when tweeting, let's look at some of the other popular words that are being tweeted with the query.
Seems like there's a lot of words that are related that are somewhat political and talking about, since "people" is a popular one, as well as "transgender people". Maybe, though, "trans" is being used in reference to themselves. I won't subject you to all the code, and just put the images of the wordclouds here.
Not quite sure why, but there are random codes that show up in the words? Maybe they are someone's username?

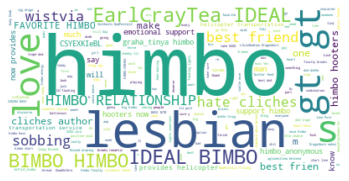
"himbo lesbian love" is my favorite grouping of words so far.


It's very interesting that gentlethem is also popular in a query with theydies, and a little less surprising that ladies is also popular alongside it (the phrase ladies, gaydies, and theydies used to be super popular).
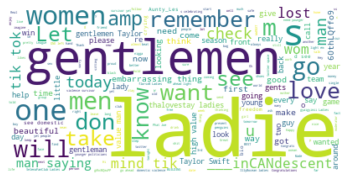
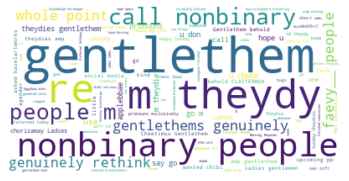
Interesting, I have seen this spelling of "theydy" a few times, but not that much. I also think it's interesting that nonbinary people shows up in this query, perhaps many of these tweets are talking about other people.

I was thinking of possibly also doing a frequency distribution for each of these, but I think this is pretty interesting too. It has given me some sort of inspiration as I go forward and definitely wanting to do some n-grams.
The next steps for this project is to look at some statistical tests, likely chi-squared and t-tests to compare the proportions of different pronoun users to determine the significance. After that, it'll be time to do some hardcore NLP! My theory right now is to use n-grams to determine who users are referring to when they use "thembo", "bimbo", etc and then some sentiment analysis to see if there is a general disatisfaction with the words or if it is typically happy and they enjoy using those words.